术语表¶
常见层¶
Flatten 压平层,把多维的数据化成一维,常用在从卷积层到全连接层的过渡
Dense 全连接层
Dropout 训练时,依据概率随机拿掉一些神经元,防止过拟合
softmax 归一化指数函数,常用来做输出层,比如分类器网络的输出有10个节点,不同节点得到了不同的置信率,后接一层softmax层就能找到
Embedding 嵌入层,常用于NPL领域的输入层,一方面能改变维度,一方面在网络中增加参数,为原本毫无关联的输入项建立关联(学习过程中调整的参数即是在动态调整这些关联),参考《深度学习中 Embedding层两大作用的个人理解》
编码¶
one-hot 编码¶
也称独热码:
- 容易计算
- 无关联
在NPL领域,比如词语集one two three可以表示为1 2 3也可以表示为[1 0 0] [0 1 0] [0 0 1],后者就是one-hot编码
当数据是与数值无关的分类,用one-hot比较合适,比如国别:
| 国别 | |
|---|---|
| A | 1(Japan) |
| B | 2(China) |
| C | 2(China) |
拆成one-hot:
| Japan | China | |
|---|---|---|
| A | 1.0 | 0 |
| B | 0 | 1.0 |
| C | 0 | 1.0 |
数据集¶
- 训练集:训练用数据
- 验证集:训练过程中,验证训练是否有效的数据,不能和测试集混在一起,因为需要用测试集来评估模型最终的泛化能力
- 测试集:用于评估模型的实际效果的数据集
参考¶
工具
- Keras API https://keras.io/zh/
- Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。
P3. Regression - Case Study¶
如何用机器学习解决问题:
- 定义预测函数
- 定义损失函数:函数对训练数据的损失越小,这个函数就越好,表示损失程度的函数就是损失函数
- 选出最优函数——梯度下降法(Gradient Descent)
梯度下降法可以得到一个局部最优解(Local optimal):
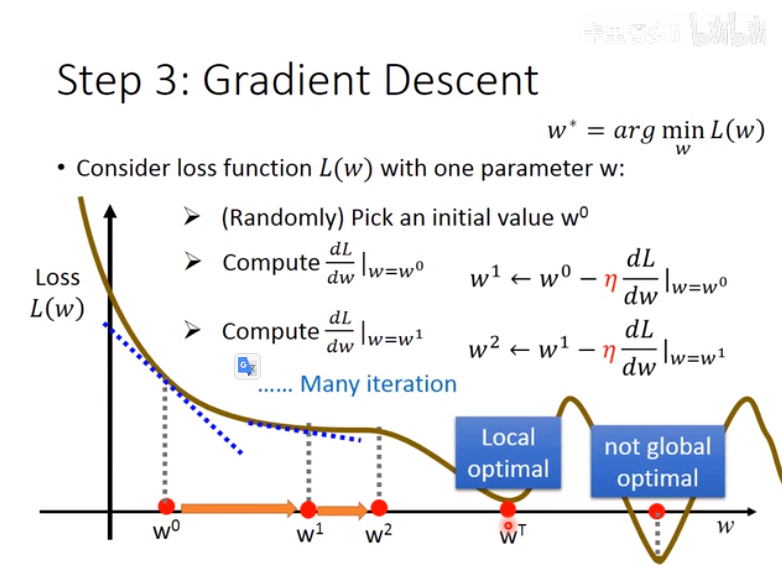
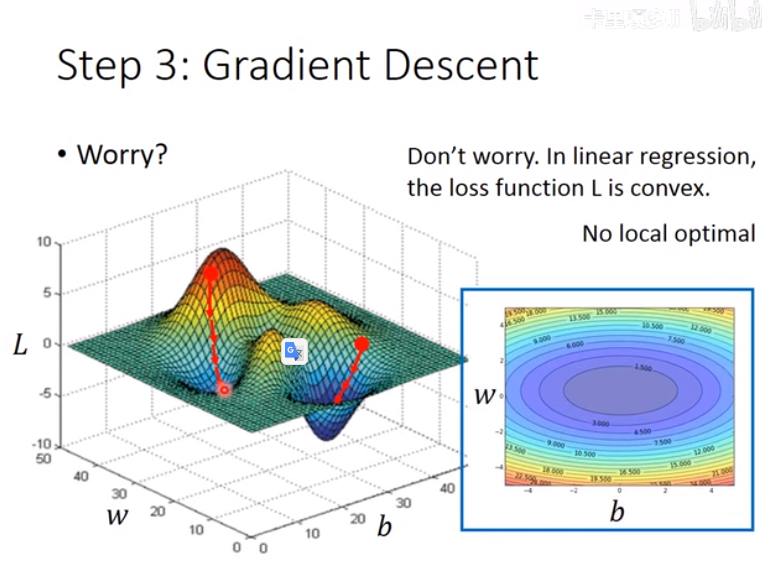
但在线性方程中,不用担心这个问题:
这里举了个例子,用pokemon的“进化前cp值”去预测“进化后的cp值”:
用二次函数比一次函数模型来做,testing data的average error要更好:
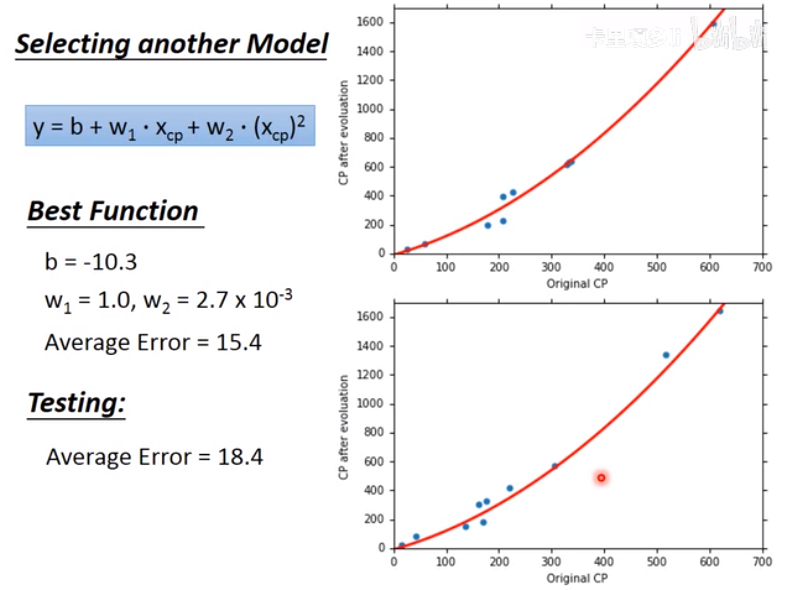
但用三次函数时,发现效果反而更差了:
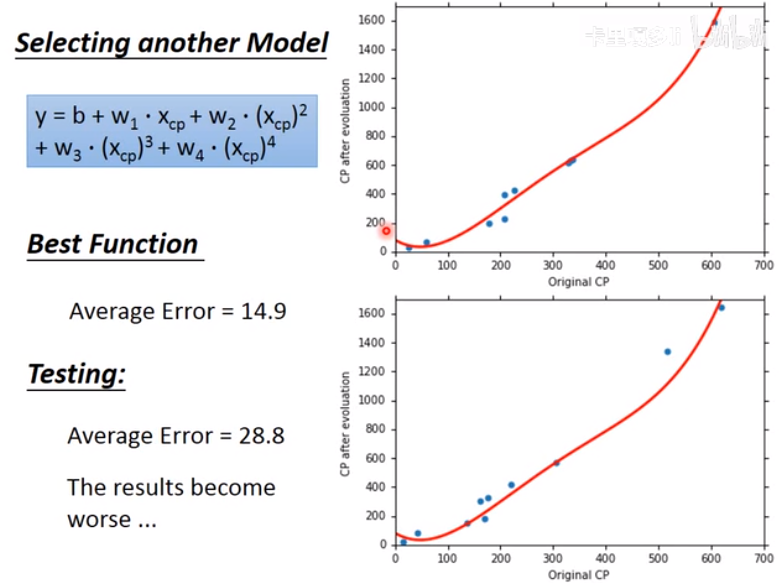
这就是过拟合(Overfitting):

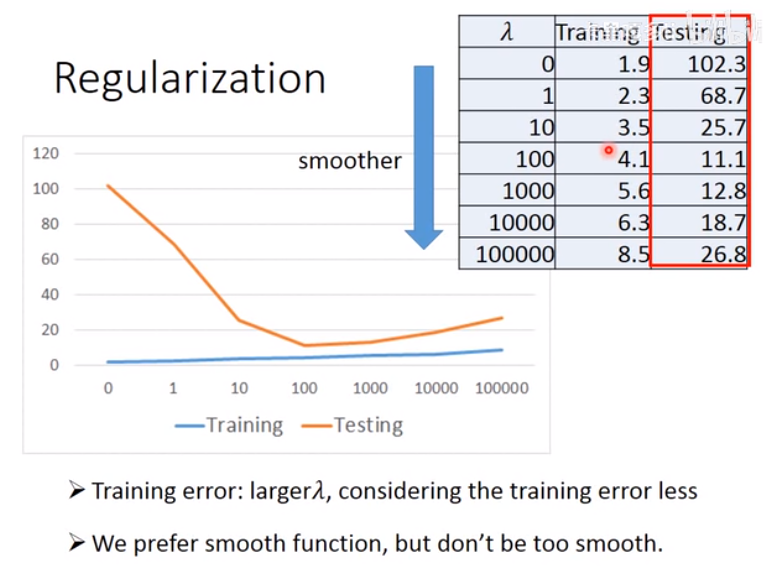
改进的方法是,损失函数中加一项,表示“尽可能地使输出对输入不敏感”(平滑),正则化“Regularization”:

平滑,但不希望太平滑:
4.Basic Concept¶
error分为bias & variance¶
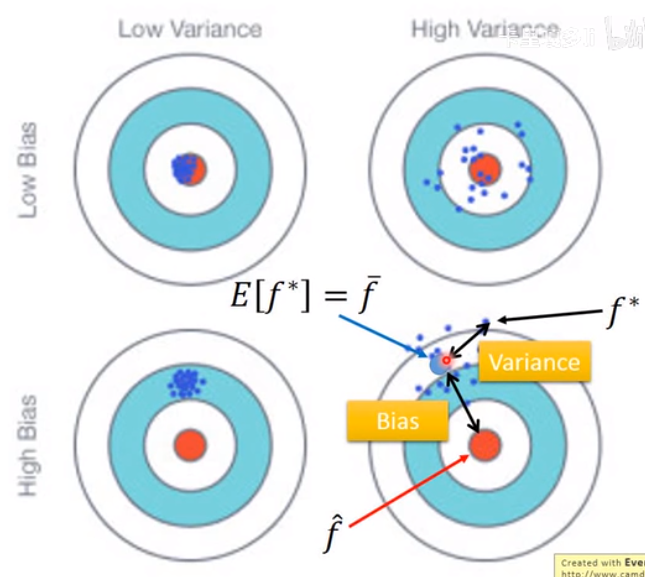
简单的model,variance会比较小;
复杂的model,bias会比较小(图里黑线为假设的目标函数,蓝线是用不同数据集算出的函数平均出(?)的函数)
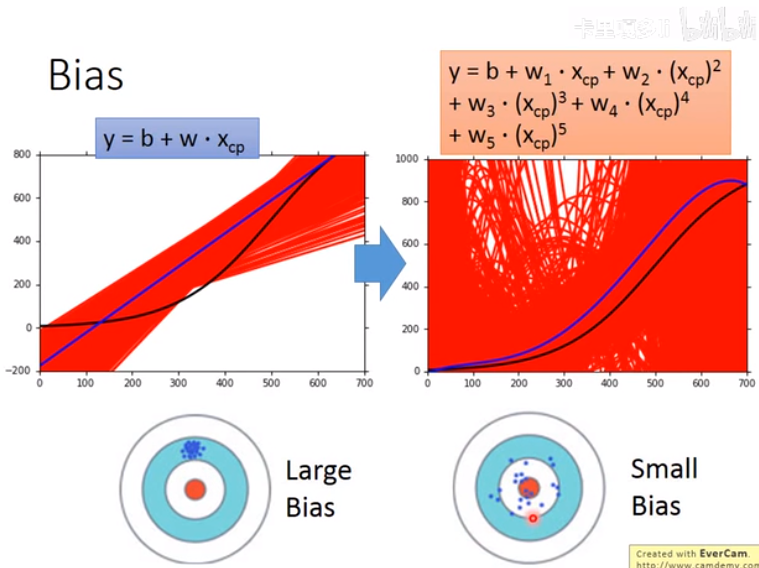
bias大的解决方法,考虑欠拟合、过拟合,改进model:
- 欠拟合可能是模型不够复杂、存在未考虑的input(特征)
- 过拟合可能是模型过于复杂
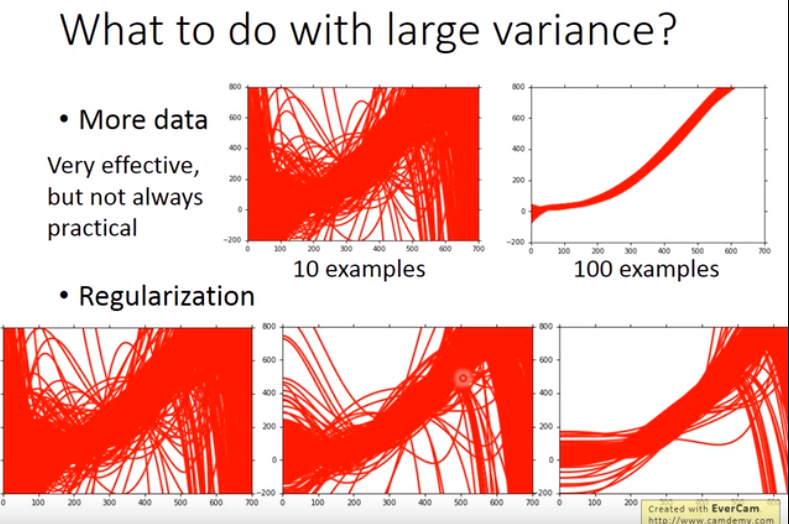
variance大的解决方法:
- 增加数据集容量
- 之前提到的正则化
模型的选择¶
数据集分为:
- 网上公开的Testing Set
- 别人私有的Testing Set
用网上公开的数据集筛选出的模型,对于私有的Testing Set肯定会有更高的误差。
正确的做法是:把数据集分为:Training Set / Validation Set,千万不要参考“验证数据集”筛选(修改)模型。

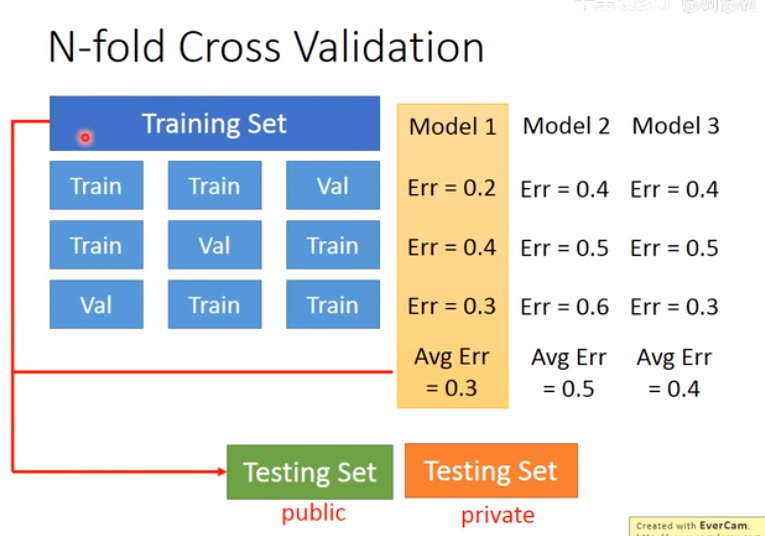
一种方法是,把数据集分为3份,两份用来训练一份用来训练,做三次,找出Avg Err最小的模型: